# ServiceLoader 类 与 SPI 机制
ServiceLoader 是 java.util 包下的一个类,一个简单的服务提供商加载工具。
下面直接来看源码文档:
英文原版:
/** | |
* A simple service-provider loading facility. | |
* | |
* <p> A <i>service</i> is a well-known set of interfaces and (usually | |
* abstract) classes. A <i>service provider</i> is a specific implementation | |
* of a service. The classes in a provider typically implement the interfaces | |
* and subclass the classes defined in the service itself. Service providers | |
* can be installed in an implementation of the Java platform in the form of | |
* extensions, that is, jar files placed into any of the usual extension | |
* directories. Providers can also be made available by adding them to the | |
* application's class path or by some other platform-specific means. | |
* | |
* <p> For the purpose of loading, a service is represented by a single type, | |
* that is, a single interface or abstract class. (A concrete class can be | |
* used, but this is not recommended.) A provider of a given service contains | |
* one or more concrete classes that extend this <i>service type</i> with data | |
* and code specific to the provider. The <i>provider class</i> is typically | |
* not the entire provider itself but rather a proxy which contains enough | |
* information to decide whether the provider is able to satisfy a particular | |
* request together with code that can create the actual provider on demand. | |
* The details of provider classes tend to be highly service-specific; no | |
* single class or interface could possibly unify them, so no such type is | |
* defined here. The only requirement enforced by this facility is that | |
* provider classes must have a zero-argument constructor so that they can be | |
* instantiated during loading. | |
* | |
* <p><a name="format"> A service provider is identified by placing a | |
* <i>provider-configuration file</i> in the resource directory | |
* <tt>META-INF/services</tt>.</a> The file's name is the fully-qualified <a | |
* href="../lang/ClassLoader.html#name">binary name</a> of the service's type. | |
* The file contains a list of fully-qualified binary names of concrete | |
* provider classes, one per line. Space and tab characters surrounding each | |
* name, as well as blank lines, are ignored. The comment character is | |
* <tt>'#'</tt> (<tt>'\u0023'</tt>, | |
* <font style="font-size:smaller;">NUMBER SIGN</font>); on | |
* each line all characters following the first comment character are ignored. | |
* The file must be encoded in UTF-8. | |
* | |
* <p> If a particular concrete provider class is named in more than one | |
* configuration file, or is named in the same configuration file more than | |
* once, then the duplicates are ignored. The configuration file naming a | |
* particular provider need not be in the same jar file or other distribution | |
* unit as the provider itself. The provider must be accessible from the same | |
* class loader that was initially queried to locate the configuration file; | |
* note that this is not necessarily the class loader from which the file was | |
* actually loaded. | |
* | |
* <p> Providers are located and instantiated lazily, that is, on demand. A | |
* service loader maintains a cache of the providers that have been loaded so | |
* far. Each invocation of the {@link #iterator iterator} method returns an | |
* iterator that first yields all of the elements of the cache, in | |
* instantiation order, and then lazily locates and instantiates any remaining | |
* providers, adding each one to the cache in turn. The cache can be cleared | |
* via the {@link #reload reload} method. | |
* | |
* <p> Service loaders always execute in the security context of the caller. | |
* Trusted system code should typically invoke the methods in this class, and | |
* the methods of the iterators which they return, from within a privileged | |
* security context. | |
* | |
* <p> Instances of this class are not safe for use by multiple concurrent | |
* threads. | |
* | |
* <p> Unless otherwise specified, passing a <tt>null</tt> argument to any | |
* method in this class will cause a {@link NullPointerException} to be thrown. | |
* | |
* | |
* <p><span style="font-weight: bold; padding-right: 1em">Example</span> | |
* Suppose we have a service type <tt>com.example.CodecSet</tt> which is | |
* intended to represent sets of encoder/decoder pairs for some protocol. In | |
* this case it is an abstract class with two abstract methods: | |
* | |
* <blockquote> | |
<pre> | |
* public abstract Encoder getEncoder(String encodingName); | |
* public abstract Decoder getDecoder(String encodingName);</pre></blockquote> | |
* | |
* Each method returns an appropriate object or <tt>null</tt> if the provider | |
* does not support the given encoding. Typical providers support more than | |
* one encoding. | |
* | |
* <p> If <tt>com.example.impl.StandardCodecs</tt> is an implementation of the | |
* <tt>CodecSet</tt> service then its jar file also contains a file named | |
* | |
* <blockquote> | |
<pre> | |
* META-INF/services/com.example.CodecSet</pre></blockquote> | |
* | |
* <p> This file contains the single line: | |
* | |
* <blockquote> | |
<pre> | |
* com.example.impl.StandardCodecs # Standard codecs</pre></blockquote> | |
* | |
* <p> The <tt>CodecSet</tt> class creates and saves a single service instance | |
* at initialization: | |
* | |
* <blockquote> | |
<pre> | |
* private static ServiceLoader<CodecSet> codecSetLoader | |
* = ServiceLoader.load(CodecSet.class);</pre></blockquote> | |
* | |
* <p> To locate an encoder for a given encoding name it defines a static | |
* factory method which iterates through the known and available providers, | |
* returning only when it has located a suitable encoder or has run out of | |
* providers. | |
* | |
* <blockquote> | |
<pre> | |
* public static Encoder getEncoder(String encodingName) { | |
* for (CodecSet cp : codecSetLoader) { | |
* Encoder enc = cp.getEncoder(encodingName); | |
* if (enc != null) | |
* return enc; | |
* } | |
* return null; | |
* }</pre></blockquote> | |
* | |
* <p> A <tt>getDecoder</tt> method is defined similarly. | |
* | |
* | |
* <p><span style="font-weight: bold; padding-right: 1em">Usage Note</span> If | |
* the class path of a class loader that is used for provider loading includes | |
* remote network URLs then those URLs will be dereferenced in the process of | |
* searching for provider-configuration files. | |
* | |
* <p> This activity is normal, although it may cause puzzling entries to be | |
* created in web-server logs. If a web server is not configured correctly, | |
* however, then this activity may cause the provider-loading algorithm to fail | |
* spuriously. | |
* | |
* <p> A web server should return an HTTP 404 (Not Found) response when a | |
* requested resource does not exist. Sometimes, however, web servers are | |
* erroneously configured to return an HTTP 200 (OK) response along with a | |
* helpful HTML error page in such cases. This will cause a {@link | |
* ServiceConfigurationError} to be thrown when this class attempts to parse | |
* the HTML page as a provider-configuration file. The best solution to this | |
* problem is to fix the misconfigured web server to return the correct | |
* response code (HTTP 404) along with the HTML error page. | |
* | |
* @param <S> | |
* The type of the service to be loaded by this loader | |
* | |
* @author Mark Reinhold | |
* @since 1.6 | |
*/ |
翻译版:
一个简单的服务提供商加载工具。 | |
服务是一组众所周知的接口和(通常是抽象的)类。服务提供者是服务的特定实现。提供程序中的类通常实现服务本身中定义的接口和类的子类。服务提供者可以以扩展的形式安装在Java平台的实现中,也就是说,jar文件放在任何常用的扩展目录中。还可以通过将提供程序添加到应用程序的类路径或通过某些其他特定于平台的方式使其可用。 | |
为了加载,服务由单个类型表示,即单个接口或抽象类。(可以使用具体类,但不建议这样做。)给定服务的提供程序包含一个或多个具体类,这些类使用特定于该提供程序的数据和代码扩展此服务类型。提供程序类通常不是整个提供程序本身,而是一个代理,它包含足够的信息来决定提供程序是否能够满足特定请求,以及可以按需创建实际提供程序的代码。提供程序类的细节往往高度特定于服务;没有一个类或接口可以统一它们,因此这里没有定义此类类型。该工具强制的唯一要求是提供程序类必须具有零参数构造函数,以便在加载过程中实例化它们。 通过在资源目录META-INF/services中放置提供者配置文件来标识服务提供者。文件名是服务类型的完全限定二进制名称。该文件包含具体提供程序类的完全限定二进制名称列表,每行一个。忽略每个名称周围的空格和制表符以及空白行。注释字符为“#”(“\u0023”,数字符号);在每行中,第一个注释字符之后的所有字符都将被忽略。文件必须以UTF-8编码。 | |
如果特定的具体提供程序类在多个配置文件中命名,或在同一配置文件中多次命名,则重复项将被忽略。命名特定提供者的配置文件不需要与提供者本身位于同一jar文件或其他分发单元中。提供程序必须可以从最初查询以查找配置文件的同一类加载器访问;注意,这不一定是实际加载文件的类加载器。 | |
提供程序的定位和实例化都是惰性的,即按需进行。服务加载器维护迄今已加载的提供程序的缓存。迭代器方法的每次调用都返回一个迭代器,该迭代器首先按实例化顺序生成缓存的所有元素,然后懒洋洋地定位和实例化任何剩余的提供程序,依次将每个提供程序添加到缓存中。可以通过重载方法清除缓存。 | |
服务加载器始终在调用者的安全上下文中执行。受信任的系统代码通常应该从特权安全上下文中调用此类中的方法及其返回的迭代器的方法。 | |
此类的实例对于多个并发线程使用是不安全的。 | |
除非另有规定,否则向此类中的任何方法传递null参数将导致引发NullPointerException。 | |
示例假设我们有一个服务类型com.Example.CodecSet,它用于表示某些协议的编码器/解码器对集。在本例中,它是一个具有两个抽象方法的抽象类: | |
public abstract Encoder getEncoder(String encodingName); | |
public abstract Decoder getDecoder(String encodingName); | |
如果提供程序不支持给定的编码,则每个方法都返回一个适当的对象或null。典型的提供程序支持多种编码。 如果com.example.impl.StandardCodecs是CodecSet服务的实现,那么它的jar文件也包含一个名为 | |
META-INF/services/com.example.CodecSet | |
此文件包含单行: | |
com.example.impl.StandardCodecs #标准编解码器 | |
CodecSet类在初始化时创建并保存单个服务实例: | |
public static ServiceLoader<CodecSet> codecSetLoader = ServiceLoader.load(CodecSet.class); | |
要为给定的编码名称定位编码器,它定义了一个静态工厂方法,该方法遍历已知和可用的提供程序,仅在找到合适的编码器或提供程序用完时返回。 | |
public static Encoder getEncoder(String encodingName) { | |
for (CodecSet cp : codecSetLoader) { | |
Encoder enc = cp.getEncoder(encodingName); | |
if (enc != null) | |
return enc; | |
} | |
return null; | |
} | |
getDecoder方法的定义类似。 | |
用法说明:如果用于提供程序加载的类加载器的类路径包含远程网络URL,则在搜索提供程序配置文件的过程中将取消引用这些URL。 此活动是正常的,尽管它可能会导致在web服务器日志中创建令人费解的条目。但是,如果未正确配置web服务器,则此活动可能会导致提供程序加载算法错误失败。 | |
当请求的资源不存在时,web服务器应返回HTTP 404(未找到)响应。然而,有时,web服务器被错误地配置为在这种情况下返回HTTP 200(OK)响应以及有用的HTML错误页面。当此类尝试将HTML页作为提供程序配置文件进行分析时,这将导致抛出ServiceConfigurationError。此问题的最佳解决方案是修复错误配置的web服务器,以返回正确的响应代码(HTTP 404)以及HTML错误页面。 | |
自: 1.6 | |
作者: 马克·莱因霍尔德 | |
类型形参: –此加载器要加载的服务类型 |
总结一下:
-
ServiceLoader 类是一个加载服务的类
-
服务是一个接口或一个抽象类(不建议使用具体类),该接口 / 抽象类的 实现类 即为 服务提供者
-
需要在
META-INF/services目录下提供配置文件来标识服务提供者- 即在此目录下新建一个文件,文件名为 服务 的全类名
- 文件内容为 服务提供者 的全类名
- 文件内容的注释符号为
# - 文件必须以
UTF-8编码
-
提供程序的定位和加载都是懒惰的
-
该类的实例是线程不安全的
至于 SPI 机制详见:Dubbo 之 SPI 实现原理详解 - 阿里云开发者社区 (aliyun.com)
下面为该文章的内容,仅作为备份使用
下面为该文章的内容,仅作为备份使用
下面为该文章的内容,仅作为备份使用
# Dubbo 之 SPI 实现原理详解
来自:Java 技术进阶 2019-10-14 7878
简介: 开篇 SPI 全称为 Service Provider Interface,是一种服务提供机制,比如在现实中我们经常会有这种场景,就是对于一个规范定义方而言(可以理解为一个或多个接口),具体的服务实现方是不可知的(可以理解为对这些接口的实现类),那么在定义这些规范的时候,就需要规范定义方能够通过一定的方式来获取到这些服务提供方具体提供的是哪些服务,而 SPI 就是进行这种定义的。
# 开篇
SPI 全称为 Service Provider Interface,是一种服务提供机制,比如在现实中我们经常会有这种场景,就是对于一个规范定义方而言(可以理解为一个或多个接口),具体的服务实现方是不可知的(可以理解为对这些接口的实现类),那么在定义这些规范的时候,就需要规范定义方能够通过一定的方式来获取到这些服务提供方具体提供的是哪些服务,而 SPI 就是进行这种定义的。
# JDK SPI 例子
说明:
- 首先规范制定方会定义一个接口 org.apache.jdk.spi.example.IHello 。
- 其次在项目目录下的 META-INF/service 名称为 org.apache.jdk.spi.example.IHello 的文件,包含 SPI 实现接口全路径。
- 通过 ServiceLoader 加载访问调用即可。
- 对于 jdk 的 SPI,其主要存在两个问题,为每个接口提供的服务一般尽量只提供一个,因为 jdk 的 SPI 默认会将所有目标文件中定义的所有子类都读取到返回使用;当定义多个子类实现时,无法动态的根据配置来使用不同的配置。
---- 定义接口 | |
package org.apache.jdk.spi.example; | |
public interface IHello { | |
void sayHello(); | |
} | |
---- 定义实现1 | |
package org.apache.jdk.spi.example; | |
public class HelloImpl1 implements IHello { | |
@Override | |
public void sayHello() { | |
System.out.println("我是Impl1"); | |
} | |
} | |
---- 定义实现2 | |
package org.apache.jdk.spi.example; | |
public class HelloImpl2 implements IHello { | |
@Override | |
public void sayHello() { | |
System.out.println("我是Impl2"); | |
} | |
} | |
---- META-INF/services目录文件 org.apache.jdk.spi.example.IHello | |
org.apache.jdk.spi.example.HelloImpl1 | |
org.apache.jdk.spi.example.HelloImpl2 | |
---- 测试文件内容 | |
package org.apache.jdk.spi.example; | |
import java.util.Iterator; | |
import java.util.ServiceLoader; | |
public class ServiceLoaderDemo { | |
public static void main(String[] args){ | |
ServiceLoader<IHello> s = ServiceLoader.load(IHello.class); | |
Iterator<IHello> iHelloIterator = s.iterator(); | |
while (iHelloIterator.hasNext()) { | |
IHello iHello = iHelloIterator.next(); | |
iHello.sayHello(); | |
} | |
} | |
} |
# Dubbo SPI 例子
- 定义 PlantsWater 的接口并通过 @SPI 注解进行注解,注解可选择带默认值。
- 将 watering () 方法使用 @Adaptive 注解进行了标注,表示该方法在自动生成的子类中是需要动态实现的方法。
- 增加 grant () 方法是为了表明不带 @Adaptive 在自动生成的子类方法内部会抛出异常。
- 为 PlantsWater 增加两个实现,AppleWater 和 BananaWater,实际调用通过参数控制。
- 在 META-INF/dubbo 下创建一个文件,该文件的名称是目标接口的全限定名,这里是 org.apache.dubbo.spi.example.PlantsWater,在该文件中需要指定该接口所有可提供服务的子类。
- 定义主函数 ExtensionLoaderDemo 模拟 SPI 调用的验证。
----定义基础应用类 | |
public interface Fruit {} | |
public class Apple implements Fruit {} | |
public class Banana implements Fruit{} | |
----定义SPI类 | |
@SPI("banana") | |
public interface PlantsWater { | |
Fruit grant(); | |
@Adaptive | |
String watering(URL url); | |
} | |
public class AppleWater implements PlantsWater { | |
public Fruit grant() { | |
return new Apple(); | |
} | |
public String watering(URL url) { | |
System.out.println("watering apple"); | |
return "watering finished"; | |
} | |
} | |
public class BananaWater implements PlantsWater { | |
public Fruit grant() { | |
return new Banana(); | |
} | |
public String watering(URL url) { | |
System.out.println("watering banana"); | |
return "watering success"; | |
} | |
} | |
----resources文件 org.apache.dubbo.spi.example.PlantsWater | |
apple=org.apache.dubbo.spi.example.AppleWater | |
banana=org.apache.dubbo.spi.example.BananaWater | |
------测试代码内容 | |
public class ExtensionLoaderDemo { | |
public static void main(String[] args) { | |
// 首先创建一个模拟用的 URL 对象 | |
URL url = URL.valueOf("dubbo://192.168.0.101:20880?plants.water=apple"); | |
// 通过 ExtensionLoader 获取一个 PlantsWater 对象,getAdaptiveExtension 已经加载了所有 SPI 类 | |
PlantsWater plantsWater = ExtensionLoader.getExtensionLoader(PlantsWater.class) | |
.getAdaptiveExtension(); | |
// 使用该 PlantsWater 调用其 "自适应标注的" 方法,获取调用结果 | |
String result = plantsWater.watering(url); | |
System.out.println(result); | |
} | |
} | |
-----实际输出内容 | |
十月 11, 2019 7:48:51 下午 org.apache.dubbo.common.logger.LoggerFactory info | |
信息: using logger: org.apache.dubbo.common.logger.jcl.JclLoggerAdapter | |
watering apple | |
watering finished | |
Process finished with exit code 0 |
# JDK 和 Dubbo SPI 简单对比
Dubbo 的扩展点加载是基于 JDK 标准的 SPI 扩展点发现机制增强而来的,Dubbo 改进了 JDK 标准的 SPI 的以下问题:
- JDK 标准的 SPI 会一次性实例化扩展点所有实现,如果有扩展实现初始化很耗时,但如果没用上也加载,会很浪费资源。
- 如果扩展点加载失败,就失败了,给用户没有任何通知。比如:JDK 标准的 ScriptEngine,如果 Ruby ScriptEngine 因为所依赖的 jruby.jar 不存在,导致 Ruby ScriptEngine 类加载失败,这个失败原因被吃掉了,当用户执行 ruby 脚本时,会报空指针异常,而不是报 Ruby ScriptEngine 不存在。
- 增加了对扩展点 IoC 和 AOP 的支持,一个扩展点可以直接 setter 注入其它扩展点。
# Dubbo SPI 实现原理
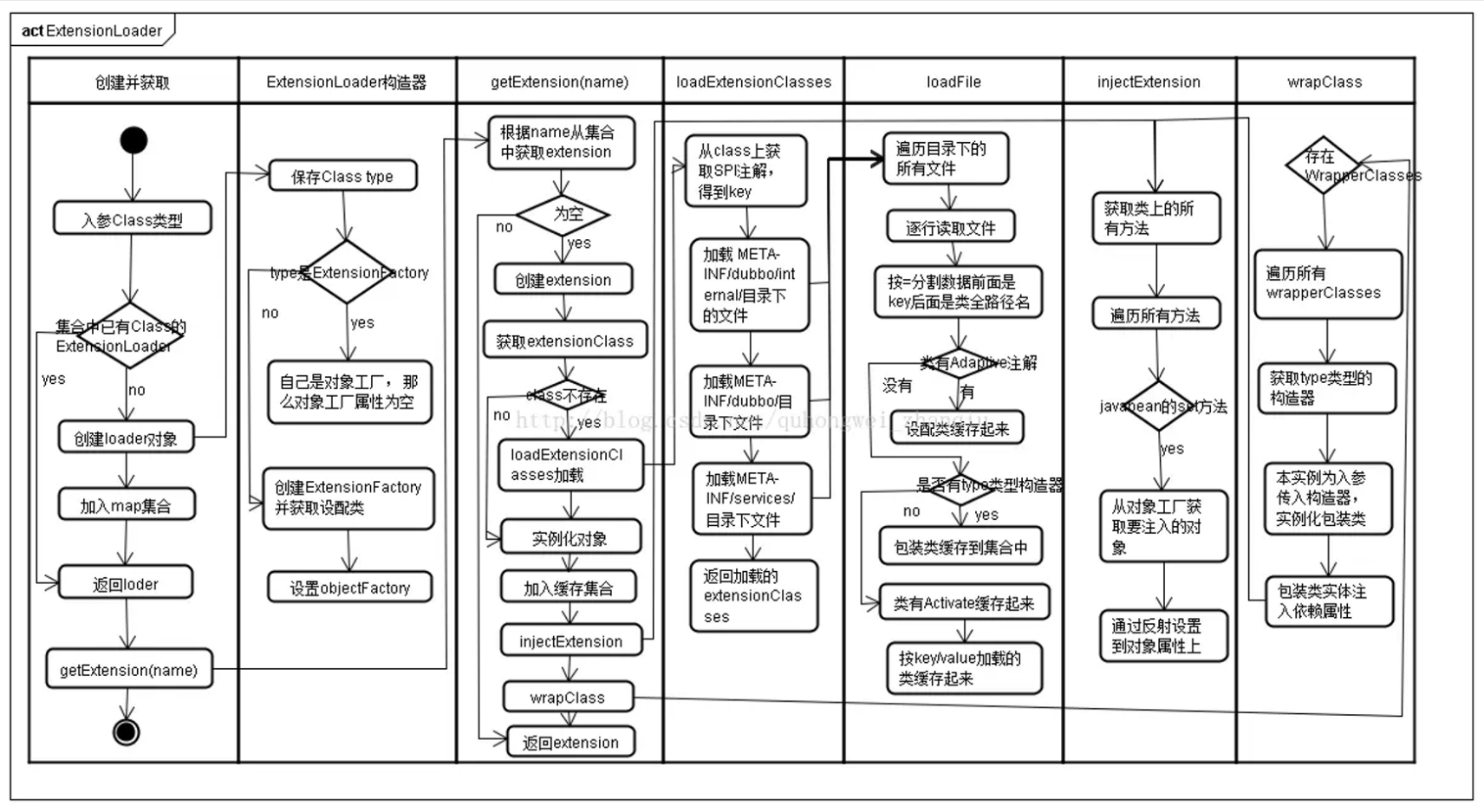
dubbo 对于 SPI 的实现主要是在 ExtensionLoader 这个类中,这个类主要有三个方法:
- getExtension ():主要用于获取名称为 name 的对应的子类的对象,这里如果子类对象如果有 AOP 相关的配置,这里也会对其进行封装;
- getAdaptiveExtension ():使用定义的装饰类来封装目标子类,具体使用哪个子类可以在定义的装饰类中通过一定的条件进行配置;
- getExtensionLoader ():加载当前接口的子类并且实例化一个 ExtensionLoader 对象。
public T getExtension(String name); | |
public T getAdaptiveExtension(); | |
public static <T> ExtensionLoader<T> getExtensionLoader(Class<T> type); |
# getExtension()
- getExtension () 方法的主要作用是获取 name 对应的子类对象返回。
- 其实现方式是首先读取定义文件中的子类,然后根据不同的子类对象的功能的不同,比如使用 @Adaptive 修饰的装饰类和用于 AOP 的 Wrapper 类,将其封装到不同的缓存中。
- 最后根据传入的 name 获取其对应的子类对象,并且使用相应的 Wrapper 类对其进行封装。
如下是 getExtension () 方法的源码:
public T getExtension(String name) { | |
if (StringUtils.isEmpty(name)) { | |
throw new IllegalArgumentException("Extension name == null"); | |
} | |
// 如果名称为 true,则返回默认的子类对象,这里默认的子类对象的 name 定义在目标接口的 @SPI 注解中 | |
if ("true".equals(name)) { | |
return getDefaultExtension(); | |
} | |
// 查看当前是否已经缓存有保存目标对象的实例的 Holder 对象,缓存了则直接返回, | |
// 没缓存则创建一个并缓存起来 | |
final Holder<Object> holder = getOrCreateHolder(name); | |
Object instance = holder.get(); | |
// 如果无法从 Holder 中获取目标对象的实例,则使用双检查法为目标对象创建一个实例 | |
if (instance == null) { | |
synchronized (holder) { | |
instance = holder.get(); | |
if (instance == null) { | |
// 创建 name 对应的子类对象的实例 | |
instance = createExtension(name); | |
holder.set(instance); | |
} | |
} | |
} | |
return (T) instance; | |
} | |
public T getDefaultExtension() { | |
getExtensionClasses(); | |
if (StringUtils.isBlank(cachedDefaultName) || "true".equals(cachedDefaultName)) { | |
return null; | |
} | |
// 通过 cachedDefaultName 去获取对应的子类实例 | |
return getExtension(cachedDefaultName); | |
} | |
private void cacheDefaultExtensionName() { | |
//cachedDefaultName 取自 SPI 的参数当中 | |
final SPI defaultAnnotation = type.getAnnotation(SPI.class); | |
if (defaultAnnotation == null) { | |
return; | |
} | |
String value = defaultAnnotation.value(); | |
if ((value = value.trim()).length() > 0) { | |
String[] names = NAME_SEPARATOR.split(value); | |
if (names.length > 1) { | |
throw new IllegalStateException("More than 1 default extension name on extension " + type.getName() | |
+ ": " + Arrays.toString(names)); | |
} | |
if (names.length == 1) { | |
cachedDefaultName = names[0]; | |
} | |
} | |
} |
- 关于对于目标对象的获取,首先是从缓存里取,没取到才会进行创建。
- 这里需要说明的是,如果传入的 name 为 true,那么就会返回默认的子类实例,而默认的子类实例是通过其名称进行映射的,该名称存储在目标接口的 @SPI 注解中。
createExtension () 方法的源码:
private T createExtension(String name) { | |
// 获取当前名称对应的子类类型,如果不存在,则抛出异常 | |
Class<?> clazz = getExtensionClasses().get(name); | |
if (clazz == null) { | |
throw findException(name); | |
} | |
try { | |
// 获取当前 class 对应的实例,如果缓存中不存在,则实例化一个并缓存起来 | |
T instance = (T) EXTENSION_INSTANCES.get(clazz); | |
if (instance == null) { | |
EXTENSION_INSTANCES.putIfAbsent(clazz, clazz.newInstance()); | |
instance = (T) EXTENSION_INSTANCES.get(clazz); | |
} | |
// 为生成的实例通过其 set 方法注入对应的实例,这里实例的获取方式不仅可以通过 SPI 的方式 | |
// 也可以通过 Spring 的 bean 工厂获取 | |
injectExtension(instance); | |
Set<Class<?>> wrapperClasses = cachedWrapperClasses; | |
if (CollectionUtils.isNotEmpty(wrapperClasses)) { | |
for (Class<?> wrapperClass : wrapperClasses) { | |
// 实例化各个 wrapper 对象,并将目标对象通过 wrapper 的构造方法传入, | |
// 另外还会通过 wrapper 对象的 set 方法对其依赖的属性进行注入 | |
instance = injectExtension((T) wrapperClass.getConstructor(type).newInstance(instance)); | |
} | |
} | |
return instance; | |
} catch (Throwable t) { | |
throw new IllegalStateException("Extension instance (name: " + name + ", class: " + | |
type + ") couldn't be instantiated: " + t.getMessage(), t); | |
} | |
} |
在 createExtension () 方法中,其主要做了三件事:
- 加载定义文件中的各个子类,然后将目标 name 对应的子类返回后进行实例化。
- 通过目标子类的 set 方法为其注入其所依赖的 bean,这里既可以通过 SPI,也可以通过 Spring 的 BeanFactory 获取所依赖的 bean,injectExtension (instance)。
- 获取定义文件中定义的 wrapper 对象,然后使用该 wrapper 对象封装目标对象,并且还会调用其 set 方法为 wrapper 对象注入其所依赖的属性。
关于 wrapper 对象,这里需要说明的是,其主要作用是为目标对象实现 AOP。wrapper 对象有两个特点:
- 与目标对象实现了同一个接口;
- 有一个以目标接口为参数类型的构造函数。这也就是上述 createExtension () 方法最后封装 wrapper 对象时传入的构造函数实例始终可以为 instance 实例的原因。
getExtensionClasses () 方法的源码
private Map<String, Class<?>> getExtensionClasses() { | |
Map<String, Class<?>> classes = cachedClasses.get(); | |
if (classes == null) { | |
synchronized (cachedClasses) { | |
classes = cachedClasses.get(); | |
if (classes == null) { | |
// 加载定义文件,并且将定义的类按照功能缓存在不同的属性中,即: | |
//a. 目标 class 类型缓存在 cachedClasses; | |
//b. wrapper 的 class 类型缓存在 cachedWrapperClasses; | |
//c. 用于装饰的 class 类型缓存在 cachedAdaptiveClass; | |
classes = loadExtensionClasses(); | |
cachedClasses.set(classes); | |
} | |
} | |
} | |
return classes; | |
} | |
private Map<String, Class<?>> loadExtensionClasses() { | |
// 获取目标接口上通过 @SPI 注解定义的默认子类对应的名称,并将其缓存在 cachedDefaultName 中 | |
cacheDefaultExtensionName(); | |
// 分别在 META-INF/dubbo/internal、META-INF/dubbo、META-INF/services 目录下 | |
// 获取定义文件,并且读取定义文件中的内容,这里主要是通过 META-INF/dubbo/internal | |
// 获取目标定义文件 | |
Map<String, Class<?>> extensionClasses = new HashMap<>(); | |
loadDirectory(extensionClasses, DUBBO_INTERNAL_DIRECTORY, type.getName()); | |
loadDirectory(extensionClasses, DUBBO_INTERNAL_DIRECTORY, type.getName().replace("org.apache", "com.alibaba")); | |
loadDirectory(extensionClasses, DUBBO_DIRECTORY, type.getName()); | |
loadDirectory(extensionClasses, DUBBO_DIRECTORY, type.getName().replace("org.apache", "com.alibaba")); | |
loadDirectory(extensionClasses, SERVICES_DIRECTORY, type.getName()); | |
loadDirectory(extensionClasses, SERVICES_DIRECTORY, type.getName().replace("org.apache", "com.alibaba")); | |
return extensionClasses; | |
} | |
private void cacheDefaultExtensionName() { | |
// 获取目标接口上通过 @SPI 注解定义的默认子类对应的名称,并将其缓存在 cachedDefaultName 中 | |
final SPI defaultAnnotation = type.getAnnotation(SPI.class); | |
if (defaultAnnotation == null) { | |
return; | |
} | |
String value = defaultAnnotation.value(); | |
if ((value = value.trim()).length() > 0) { | |
String[] names = NAME_SEPARATOR.split(value); | |
if (names.length > 1) { | |
throw new IllegalStateException("More than 1 default extension name on extension " + type.getName() | |
+ ": " + Arrays.toString(names)); | |
} | |
if (names.length == 1) { | |
cachedDefaultName = names[0]; | |
} | |
} | |
} |
- loadExtensionClasses () 主要是分别从三个目录中读取定义文件,读取该文件,并且进行缓存。
loadDirectory () 方法的源码:
private void loadDirectory(Map<String, Class<?>> extensionClasses, String dir, String type) { | |
String fileName = dir + type; | |
try { | |
Enumeration<java.net.URL> urls; | |
ClassLoader classLoader = findClassLoader(); | |
// 加载定义文件 | |
if (classLoader != null) { | |
urls = classLoader.getResources(fileName); | |
} else { | |
urls = ClassLoader.getSystemResources(fileName); | |
} | |
if (urls != null) { | |
while (urls.hasMoreElements()) { | |
// 对定义文件进行遍历,依次加载定义文件的内容 | |
java.net.URL resourceURL = urls.nextElement(); | |
loadResource(extensionClasses, classLoader, resourceURL); | |
} | |
} | |
} catch (Throwable t) { | |
logger.error("Exception occurred when loading extension class (interface: " + | |
type + ", description file: " + fileName + ").", t); | |
} | |
} | |
private void loadResource(Map<String, Class<?>> extensionClasses, ClassLoader classLoader, java.net.URL resourceURL) { | |
try { | |
try (BufferedReader reader = new BufferedReader(new InputStreamReader(resourceURL.openStream(), StandardCharsets.UTF_8))) { | |
String line; | |
while ((line = reader.readLine()) != null) { | |
final int ci = line.indexOf('#'); | |
if (ci >= 0) { | |
line = line.substring(0, ci); | |
} | |
line = line.trim(); | |
if (line.length() > 0) { | |
try { | |
String name = null; | |
int i = line.indexOf('='); | |
if (i > 0) { | |
name = line.substring(0, i).trim(); | |
line = line.substring(i + 1).trim(); | |
} | |
if (line.length() > 0) { | |
loadClass(extensionClasses, resourceURL, Class.forName(line, true, classLoader), name); | |
} | |
} catch (Throwable t) { | |
IllegalStateException e = new IllegalStateException("Failed to load extension class (interface: " + type + ", class line: " + line + ") in " + resourceURL + ", cause: " + t.getMessage(), t); | |
exceptions.put(line, e); | |
} | |
} | |
} | |
} | |
} catch (Throwable t) { | |
logger.error("Exception occurred when loading extension class (interface: " + | |
type + ", class file: " + resourceURL + ") in " + resourceURL, t); | |
} | |
} |
- 这里主要是对每个目录进行加载,然后依次加载定义文件的内容,而对定义文件内容的处理主要是在 loadResource () 方法中,在对文件中每一行记录进行处理之后,其其最终是调用的 loadClass () 方法加载目标 class 的。
loadClass () 方法的源码
private void loadClass(Map<String, Class<?>> extensionClasses, java.net.URL resourceURL, Class<?> clazz, String name) throws NoSuchMethodException { | |
// 如果加载得到的子类不是目标接口的实现类,则抛出异常 | |
if (!type.isAssignableFrom(clazz)) { | |
throw new IllegalStateException("Error occurred when loading extension class (interface: " + | |
type + ", class line: " + clazz.getName() + "), class " | |
+ clazz.getName() + " is not subtype of interface."); | |
} | |
// 如果子类上标注有 @Adaptive 注解,说明其是一个装饰类,则将其缓存在 cachedAdaptiveClass 中, | |
// 需要注意的是,一个接口只能为其定义一个装饰类 | |
if (clazz.isAnnotationPresent(Adaptive.class)) { | |
cacheAdaptiveClass(clazz); | |
// 这里判断子类是否是一个 wrapper 类,判断方式就是检查其是否有只含一个目标接口类型参数的构造函数, | |
// 有则说明其是一个 AOP 的 wrapper 类 | |
} else if (isWrapperClass(clazz)) { | |
cacheWrapperClass(clazz); | |
} else { | |
// 走到这里说明当前子类不是一个功能型的类,而是最终实现具体目标的子类 | |
clazz.getConstructor(); | |
if (StringUtils.isEmpty(name)) { | |
name = findAnnotationName(clazz); | |
if (name.length() == 0) { | |
throw new IllegalStateException("No such extension name for the class " + clazz.getName() + " in the config " + resourceURL); | |
} | |
} | |
String[] names = NAME_SEPARATOR.split(name); | |
if (ArrayUtils.isNotEmpty(names)) { | |
// 缓存 ActivateClass 类 | |
cacheActivateClass(clazz, names[0]); | |
// 将目标子类缓存到 extensionClasses 中 | |
for (String n : names) { | |
cacheName(clazz, n); | |
saveInExtensionClass(extensionClasses, clazz, n); | |
} | |
} | |
} | |
} | |
private void cacheActivateClass(Class<?> clazz, String name) { | |
// 获取子类上的 @Activate 注解,该注解的主要作用是对子类进行分组的, | |
// 对于分组之后的子类,可以通过 getActivateExtension () 来获取 | |
Activate activate = clazz.getAnnotation(Activate.class); | |
if (activate != null) { | |
cachedActivates.put(name, activate); | |
} else { | |
// 兼容 alibaba 版本的注解 | |
com.alibaba.dubbo.common.extension.Activate oldActivate = clazz.getAnnotation(com.alibaba.dubbo.common.extension.Activate.class); | |
if (oldActivate != null) { | |
cachedActivates.put(name, oldActivate); | |
} | |
} | |
} | |
private void saveInExtensionClass(Map<String, Class<?>> extensionClasses, Class<?> clazz, String name) { | |
// 将目标子类缓存到 extensionClasses 中 | |
Class<?> c = extensionClasses.get(name); | |
if (c == null) { | |
extensionClasses.put(name, clazz); | |
} else if (c != clazz) { | |
String duplicateMsg = "Duplicate extension " + type.getName() + " name " + name + " on " + c.getName() + " and " + clazz.getName(); | |
logger.error(duplicateMsg); | |
throw new IllegalStateException(duplicateMsg); | |
} | |
} |
loadClass () 方法主要作用是对子类进行划分,这里主要划分成了三部分:
- 使用 @Adaptive 注解标注的装饰类;
- 包含有目标接口类型参数构造函数的 wrapper 类
- 目标处理具体业务的子类。
总结而言,getExtension () 方法主要是获取指定名称对应的子类。在获取过程中,首先会从缓存中获取是否已经加载过该子类,如果没加载过则通过定义文件加载,并且使用获取到的 wrapper 对象封装目标对象返回。
# getAdaptiveExtension()
- ExtensionLoader 在加载了定义文件之后会对子类进行一个划分,使用 @Adaptive 进行标注的子类和使用 @Adaptive 标注子类方法。
- 使用 @Adaptive 进行标注的子类该子类的作用主要是用于对目标类进行装饰的,从而实现一定的目的。
- 使用 @Adaptive 进行标注的方法,其使用的方式主要是在目标接口的某个方法上进行标注,这个时候,dubbo 就会通过 javassist 字节码生成工具来动态的生成目标接口的子类对象,该子类会对该接口中标注了 @Adaptive 注解的方法进行重写,而其余的方法则默认抛出异常,通过这种方式可以达到对特定的方法进行修饰的目的。
getAdaptiveExtension () 方法源码
public T getAdaptiveExtension() { | |
// 从缓存中获取装饰类的实例,存在则直接返回,不存在则创建一个缓存起来,然后返回 | |
Object instance = cachedAdaptiveInstance.get(); | |
if (instance == null) { | |
if (createAdaptiveInstanceError != null) { | |
throw new IllegalStateException("Failed to create adaptive instance: " + | |
createAdaptiveInstanceError.toString(), | |
createAdaptiveInstanceError); | |
} | |
synchronized (cachedAdaptiveInstance) { | |
instance = cachedAdaptiveInstance.get(); | |
if (instance == null) { | |
try { | |
// 创建一个装饰类的实例 | |
instance = createAdaptiveExtension(); | |
cachedAdaptiveInstance.set(instance); | |
} catch (Throwable t) { | |
createAdaptiveInstanceError = t; | |
throw new IllegalStateException("Failed to create adaptive instance: " + t.toString(), t); | |
} | |
} | |
} | |
} | |
return (T) instance; | |
} |
- 从缓存中获取目标类的实例,不存在则创建一个该实例。
createAdaptiveExtension () 方法源码
private T createAdaptiveExtension() { | |
try { | |
return injectExtension((T) getAdaptiveExtensionClass().newInstance()); | |
} catch (Exception e) { | |
throw new IllegalStateException("Can't create adaptive extension " + type + ", cause: " + e.getMessage(), e); | |
} | |
} | |
private Class<?> getAdaptiveExtensionClass() { | |
// 获取目标 extensionClasses,如果无法获取到,则在定义文件中进行加载 | |
getExtensionClasses(); | |
// 如果目标类型有使用 @Adaptive 标注的子类型,则直接使用该子类作为装饰类 | |
if (cachedAdaptiveClass != null) { | |
return cachedAdaptiveClass; | |
} | |
// 如果目标类型没有使用 @Adaptive 标注的子类型,则尝试在目标接口中查找是否有使用 @Adaptive 标注的 | |
// 方法,如果有,则为该方法动态生成子类装饰代码 | |
return cachedAdaptiveClass = createAdaptiveExtensionClass(); | |
} | |
private Class<?> createAdaptiveExtensionClass() { | |
// 创建子类代码的字符串对象 | |
String code = new AdaptiveClassCodeGenerator(type, cachedDefaultName).generate(); | |
// 获取当前 dubbo SPI 中定义的 Compiler 接口的子类对象,默认是使用 javassist, | |
// 然后通过该对象来编译生成的 code,从而动态生成一个 class 对象 | |
ClassLoader classLoader = findClassLoader(); | |
org.apache.dubbo.common.compiler.Compiler compiler = ExtensionLoader.getExtensionLoader(org.apache.dubbo.common.compiler.Compiler.class).getAdaptiveExtension(); | |
return compiler.compile(code, classLoader); | |
} |
- createAdaptiveExtension () 首先委托给 getAdaptiveExtensionClass () 方法获取一个装饰类实例,然后通过 injectExtension () 方法调用该实例的 set 方法来注入其所依赖的属性值。
- 对于没有使用 @Adaptive 标注的子类时,才会使用 Javassist 来为目标接口生成其子类的装饰方法。
- 对于使用 @Adaptive 标注的子类时,直接返回子类。
- createAdaptiveExtensionClass () 动态生成目标接口的子类字符串,然后通过 javassit 来编译该子类字符串,从而动态生成目标 class。
# getExtensionLoader()
public static <T> ExtensionLoader<T> getExtensionLoader(Class<T> type) { | |
if (type == null) { | |
throw new IllegalArgumentException("Extension type == null"); | |
} | |
if (!type.isInterface()) { | |
throw new IllegalArgumentException("Extension type (" + type + ") is not an interface!"); | |
} | |
if (!withExtensionAnnotation(type)) { | |
throw new IllegalArgumentException("Extension type (" + type + | |
") is not an extension, because it is NOT annotated with @" + SPI.class.getSimpleName() + "!"); | |
} | |
ExtensionLoader<T> loader = (ExtensionLoader<T>) EXTENSION_LOADERS.get(type); | |
if (loader == null) { | |
EXTENSION_LOADERS.putIfAbsent(type, new ExtensionLoader<T>(type)); | |
loader = (ExtensionLoader<T>) EXTENSION_LOADERS.get(type); | |
} | |
return loader; | |
} |
- 对于 ExtensionLoader 的获取,其实现过程比较简单,主要是从缓存中获取,如果缓存不存在,则实例化一个并且缓存起来。
# ExtensionLoader 加载流程图